

This year at the Data Day 2017 conference in Austin,TX, keynote speaker Emil Eifrem declared 2017 the Year of Graph. Graph data storage certainly is becoming more mainstream, with a myriad of both commercial and open-source options currently available and maturing at an accelerated pace. But so what? Why should user experience practitioners, or anyone else that is not a database administrator, care about this trend in data storage technology? Because of certain aspects of the nature of graph data, unique opportunities arise when presenting this data to the end-user and, perhaps more important, novel perils in usability challenges arise. As a UX practitioner, your tried-and-true methods of designing interfaces could land you in unfamiliar territory and potentially hot water with some of your users. In this post I’ll outline some of the challenges, opportunities and strategies to successfully design within a graph ecosystem.
What is a graph?
Graph is not a new concept. Its roots are in a mathematical theory cooked up over 300 years ago. Graph theory is the mathematical modeling of relationships between two or more “things.” These “things” are frequently referred to as nodes or vertices, and the connections between these “things” are often referred to as edges. These models are often used to describe relationships that occur all the time—social networks, transportation systems, computer networks, etc…
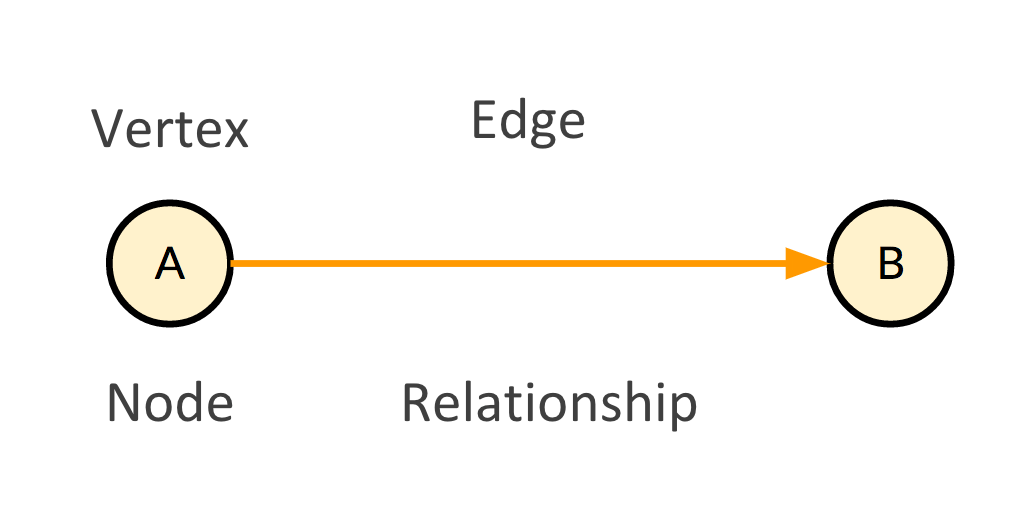
It turns out that modeling how these things are connected to other things has some advantages when looking at patterns and deriving meaning from them.These patterns can be mathematically brought to relief through algorithmic methods (more on this later). Properties or attributes can also be given to nodes and edges to decorate them with even more information. Somewhere along the way, technologists figured out these mathematical models could be used to store data (in a graph database) and retrieved by mathematically traversing these graph models. In the age of NoSQL, graph databases offer a pretty interesting way of storing and retrieving information. But these relationship-based models get complex and big very quickly. While the information is rich and allows us to gain new insights, you have to know how to work with it.
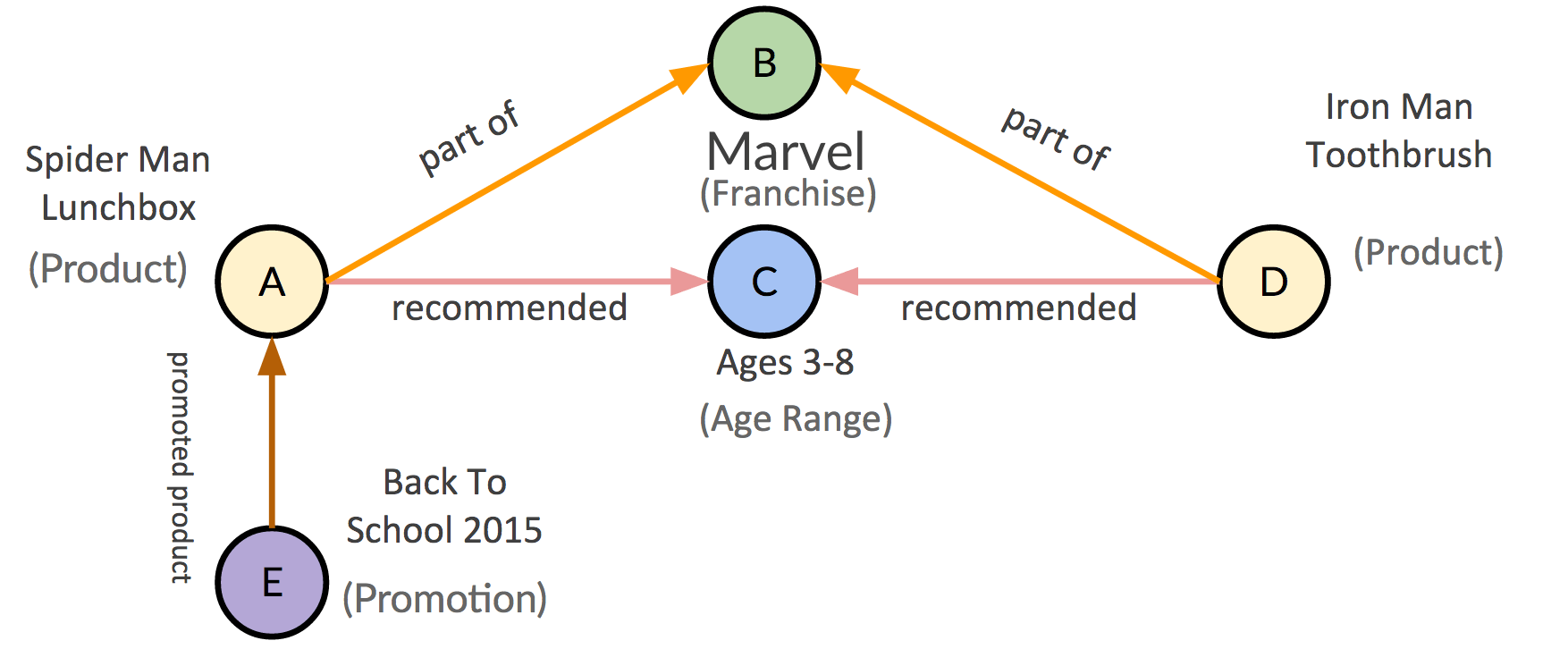
Considering the data differently and new opportunities
For much of my career I’ve relied on a comfortable “design by contract” relationship with back-end developers. After some preliminary requirements were gathered, developers provided me with a rough data schema for a given solution and we were independently off to the races. Everyone knew how relational data worked and where the limitations were; web designers were expected to craft an experience with those constraints in mind. I got really good at this, too. I could often anticipate what was going to be hard or data-intensive with little or no guidance from back-end developers before my designs were complete. Relational data is almost always conceptualized as a cube of data. The strategies for exposing the user to this data are well-known—reduce dimensions, slice the cube or zoom in on a region to filter the data to something manageable for the user. The schema of a relational database is usually predefined and relatively static. So rigidly tailoring a user experience to navigating these dimensions is something that user experience professionals are very familiar with.

Graph data can be very different. Graph data can certainly be conceptually coerced into a cube and treated just like relational data, and sometimes that is the most appropriate way to expose it to the end-user. But extracting data, or traversing the graph, is where both the challenges and the opportunities reside. Due to the distinct mathematical nature of graph data, information about relationships can be derived that would otherwise be very hard to expose through other data models. Traversing a graph with certain algorithms allows you to, for example, show key influencers in social networks, clusters of communities in customer reviews or weak points in electrical grids. This is achieved by looking at the nature of connections between nodes and degrees of separation between associated nodes in the graph. These new insights into data give a designer novel tools to craft for a given user experience. But this opportunity comes at a price, namely more complexity. The UX perils of this added complexity is something I’ve touched on before, so I won’t rehash it here, but graph data definitely has a propensity to tip toward complexity and size, and quickly. Here are a few things to watch out for:
1. You can’t always count on a schema to guide you.
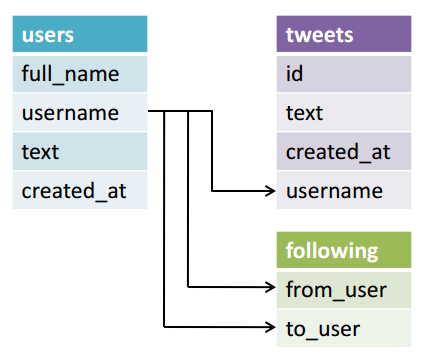
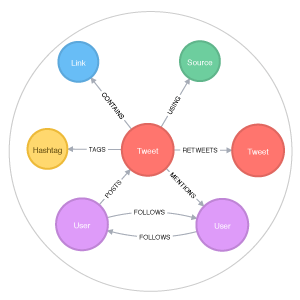
Many graph databases do not need schemas; their models can grow and change dynamically. Best practices may dictate that a schema is defined at the outset, but that schema is basically a convention and can’t necessarily be thought of as an analog to a relational database schema. What does that mean for UX designers? It means that your dimensions could change, so your presentation may need to account for showing data relationships in a dynamic way. The structure of your information architecture may need to be flexible enough to account for fundamental shifts in the data. Not all use cases will fall into this category, but graph tends to necessitate data exploration. If this is the case, the changing relationships of the data may be the dominant mode of navigation. The path the user takes to discover data provides the context and may actually be as important as the data itself. For these scenarios, Ben Shneiderman's Information Seeking Mantra (overview first, zoom and filter, then details-on-demand) can be an invaluable guide to data presentation and techniques in progressive disclosure.
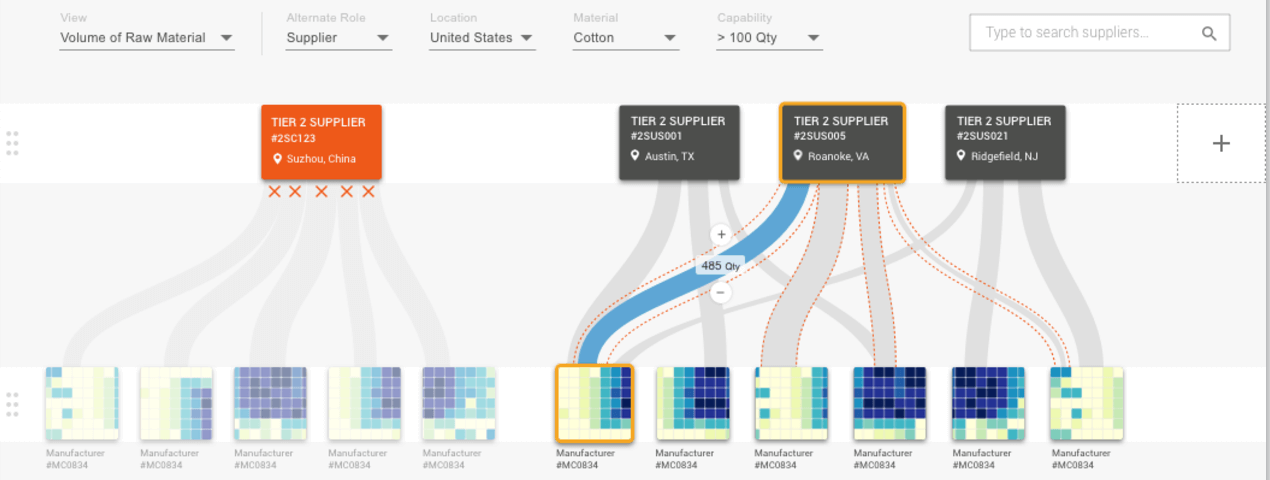
2. Traditional UI patterns may not always work.
Graph data is often comprised of many-to-many relationships. What does this mean to a designer? Tree views will often be a suboptimal way of showing hierarchy because entities often have multiple parents. In fact, the utility in exposing the data hinges on showing that children roll up to many different parents. This breaks many hierarchical user interface patterns based on file folder conventions. Pagination and aggregate counts can also become problematic with data coming from a graph. Because spidering out to all the nested relationships of nodes can become a very expensive (computationally intensive) operation, special care should be taken not to assume a UI can, by default, cast a wide net when retrieving data, such as in the case of search results. Furthermore, presenting those results in a displayed number of paged chunks may also prove to be difficult or computationally intensive. This is commonly the culprit for downstream usability issues such as performance lag and unresponsiveness. For this reason, it may be more appropriate to overtly and aggressively broadcast top relevance matches and paginate using an open-ended model such as ‘Load more records’ or just loading on an explicit interaction like scrolling, rather than a finite set of pages (Facebook and Twitter use this tactic liberally).
3. Don’t jump to graph visualization as presentation method too quickly (or at all).
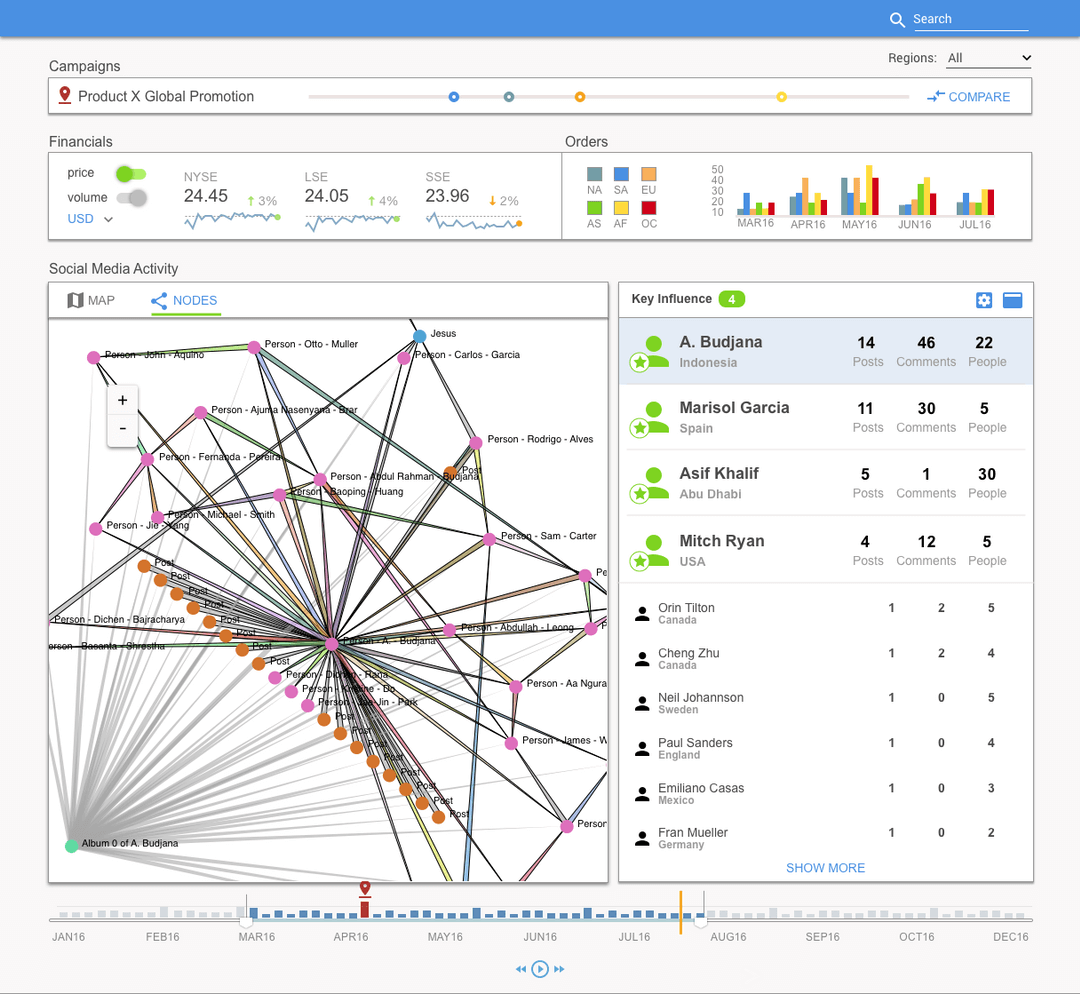

It is easy to jump to conclusions when data is modeled as a graph in data storage or in the business logic layers of an application. A natural conclusion would be to expose this model in the presentation layer directly. Storage and modeling in the UI are two separate things; there are optimal times to expose it and times to obfuscate it. Above all, a UX designer needs to keep in mind that exposing graph data often comes at a very high price: performance and scalability. While traditional design principles may be sound, they often can’t account for the sheer amount of data displayed in the UI. This problem often manifests as one part technical, one part UX. Particularly, when dealing with web technologies, creating a network diagram can be a costly endeavor to render. Adding interactivity and progressive disclosure will only exacerbate performance issues. Even if technology can surmount performance issues, network diagrams or other complex relationship-based visualizations, users still have to contend with scaling cognitively to interpret and navigate large amounts of information. While such visualizations most directly represent the relationship of the data, they can be difficult to interact with and understand to the untrained eye. A strategy to mitigate both the UX and technical issues is to reveal this complexity only after the user has filtered down the data using more conventional means. After the user has filtered to the point where a manageable sub-graph is displayed as a network diagram, I often contextualize that visualization with standard data visualizations and tabular data. As in the example above (left), often the primary interactions can be driven outside the network diagram.
4. You’re going to need to experience the data to understand it.
As stated before, a graph-based schema (if it even exists) my be a highly dynamic entity. Often, it is not enough to understand a snapshot of node/edge category relationships. To truly understand how to design for these data sets, a UX designer may need to actually traverse the data. This requires that a designer become more conversant in some data exploration techniques traditionally confined to developers and data scientists. As I’ll touch on in a moment, the method of data traversal is often the biggest hint of how the data should manifest to the user in the presentation layer of the application. Again, your biggest issues to factor in are going to be size and complexity. Without understanding the data itself, crafting a proper UI to mitigate issues that arise with performance and cognitive load are very difficult without experiencing the data in a graph data firsthand. The relationships can grow so organically and can be so intertwined that sometimes only data exploration techniques can lead you to the most appropriate design for the problem.
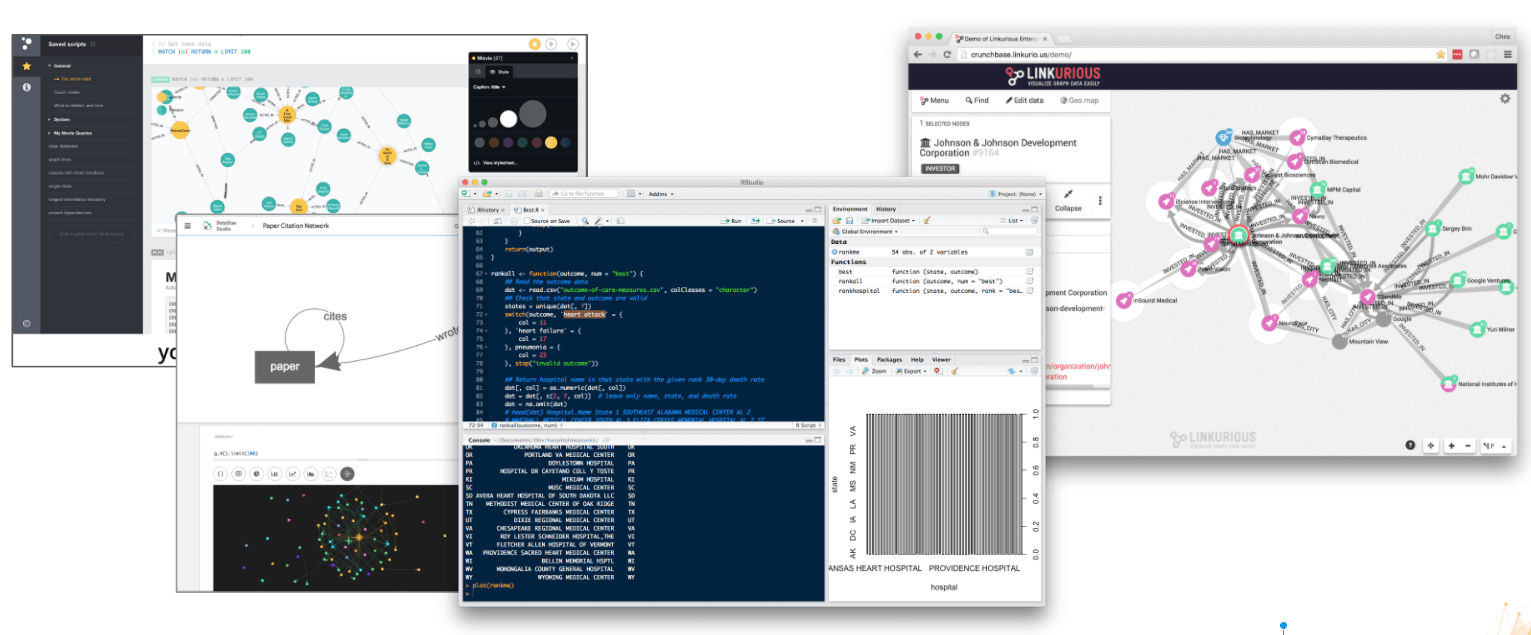
So as a designer, how does one experience graph data before there is an application to do so? It sounds like a chicken-and-egg problem and one not easily overcome. It requires 1) access to the data, and 2) some understanding of data exploration techniques. Accessing data can be tricky; it will almost always involve close involvement with data architects and/or developers. Some graph database technologies such as DataStax Graph and Neo4J offer web-based tools to access and query those graph databases. But even then, that requires querying databases to see the resulting data. There are some business intelligence reporting applications such as Linkurious that can introspect a graph database to provide insight as well. I have even resorted to accessing exports of data with tools such as Python or R. Access to data is only the first step, however. A UX designer needs to know what questions to ask. To formulate these “questions,” I recommend taking cues from common data science practices—deductive vs. conceptual data, declarative vs. exploratory use cases, ordinal, nominal, cardinal measures, etc… A deep dive into data science and statistical analysis techniques are beyond the scope of this particular article but I vigorously encourage my UX design colleagues to get acquainted with these disciplines. I firmly believe it is the future of data-driven UX if not UX in general.
So what’s the UX payoff for all the added challenges?

What do we gain from the added challenges and complexity that working with graph data brings? Answer: Insight. Graphs can algorithmically tell us things that are harder or even sometimes impossible to do through other means. As UX professionals, we now have a set of tools that offer new business intelligence and visibility to empower users to get things done and make important decisions. We have the ability to achieve feats such as bringing to relief communities hidden in big data, calculating an individual’s influence, detecting points of failure, dynamically finding the shortest path between two locations, ranking search results by relevancy, or managing dependencies. This offers a host of novel ways to craft a user experience that had largely been technically infeasible or cost prohibitive. As UX practitioners, to seize these capabilities we need to grow our skills and open our best practices to include the tools and methods necessary to work with this novel data type. Next in this series I’ll cover what to do once we understand the data—tips and tricks on presenting it to the end-user.
Also check out: Webinar: Is Your Graph Database Falling Down on the Job?
March 8 @11am CST
Lynn Pausic, VP of User Experience at Expero, will discuss many of the topics covered in this article as well as best practices for visualizing graph data and moving your graph technical experimentation to the next level, a proof of concept that will build business consensus.
Next up in this series:
Minding the Sharp Edges: UX Considerations with Graph
Part 2: How and when to best visualize graph data
Third in the series:
Minding the Sharp Edges: UX Considerations with Graph
Part 3: Usability testing challenges presented by graph data
We are ready to accelerate your business. Get in touch.
Tell us what you need and one of our experts will get back to you.